Lo importante es considerar que los símbolos se pueden ordenar y
reordenar de forma utilizable y se les denomina información.
Los datos son símbolos que describen condiciones, hechos, situaciones
o valores. Los datos se caracterizan por no contener ninguna
información. Un dato puede significar un número, una letra, un signo
ortográfico o cualquier símbolo que represente una cantidad, una
medida, una palabra o una descripción.
La importancia de los datos está en su capacidad de asociarse dentro de
un contexto para convertirse en información. Por si mismos los datos no
tienen capacidad de comunicar un significado y por tanto no pueden
afectar el comportamiento de quien los recibe. Para ser útiles, los datos
deben convertirse en información para ofrecer un significado,
conocimiento, ideas o conclusiones
El concepto de Información:
La información no es un dato conjunto cualquiera de ellos. Es más bien
una colección de hechos significativos y pertinentes, para el organismo u
organización, que los percibe. La definición de información es la
siguiente: Información es un conjunto de datos significativos y pertinentes
que describan sucesos o entidades.
DATOS SIGNIFICATIVOS. Para ser significativos, los datos deben
constar de símbolos reconocibles, estar completos y expresar una idea
no ambigua.
Continuamente, las personas deben elegir entre varias opciones aquella que consideran más
conveniente. Es decir, han de tomar gran cantidad de decisiones en su vida cotidiana, en mayor o menor grado
importantes, a la vez que fáciles o difíciles de adoptar en función de las consecuencias o resultados derivados
de cada una de ellas.
Por lo general hemos definido la toma de decisiones como la “selección entre alternativas". Esta manera
de considerar la toma de decisiones es bastante simplista, porque la toma de decisiones es un proceso en lugar
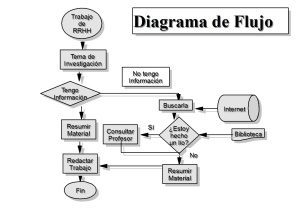
de un simple acto de escoger entre diferentes alternativas. La figura siguiente nos muestra el proceso de toma
de decisiones como una serie de ocho pasos que comienza con la identificación del problema, los pasos para
seleccionar una alternativa que pueda resolver el problema, y concluyen con la evaluación de la eficacia de la
decisión. Este proceso se puede aplicar tanto a sus decisiones personales como a una acción de una empresa, a
su vez también se puede aplicar tanto a decisiones individuales como grupales.
Una de los cimientos más esenciales en las que se fundamenta la toma de decisiones en cualquier empresa es el aprovechamiento del conocimiento, éste proviene directamente de la persona encargada de realizarla y tenemos como supuesto que cuenta con la información del contexto, de la industria y tiene la capacidad de seleccionar el curso de acción más favorable a la organización.
Cuando se toman decisiones en las empresas éstas deben de cumplir con ciertas características, ya que de esto depende en muchas ocasiones el éxito o fracaso de la organización, podemos mencionar entre otras:
- Oportunas
- Rápidas
- Informadas
- Efectivas
- Eficientes (en uso de recursos)
La importancia de la información para las organizaciones radica en que es un recurso esencial, éstas la utilizan al desempeñar sus operaciones diarias y de manera estratégica para la búsqueda de un alto nivel competitivo y crecimiento.
Referencia bibliográfica: Robbins, S.P. (1994; pág 157)
Referencia web: http://blog.corponet.com.mx/la-importancia-de-la-informacion-para-la-toma-de-decisiones-en-la-empresa
Una base de datos relacional es una colección de elementos de datos organizados en un conjunto de tablas formalmente descritas desde la que se puede acceder a los datos o volver a montarlos de muchas maneras diferentes sin tener que reorganizar las tablas de la base. La base de datos relacional fue inventada por E.F. Codd en IBM en 1970.
El modelo relacional, por tanto, es una más de esas estructuras. Su aportación consiste en proponer un modelo basado en la teoría de conjuntos, concretamente en el concepto conjuntista de relación, así como en definir un álgebra que permite realizar operaciones con ficheros que generan nuevos ficheros.

El modelo pronto despertó expectación por su elegancia y otros teóricos realizaron interesantes aportaciones, como P. Chen, quien propuso un sistema para analizar la información y dividirla en ficheros basado en los conceptos de entidad y relación. En poco tiempo, si lo comparamos con el tiempo que tardaron otros desarrollos teóricos en llegar al mercado, la industria fue capaz de ofrecer programas relacionales que proporcionaban a las empresas un medio seguro para el almacenamiento de todos sus datos corporativos.
El prestigio de los sistemas relacionales no dejó de crecer, hasta el punto en que, hoy, para la mayor parte de los informáticos hablar de bases de datos es hablar de sistemas relacionales, como si no existieran, ni hubieran existido nunca, otras estructuras de ficheros.
Una colección o depósito de datos integrados con redundancia controlada y con una estructura que refleje las interrelaciones y restricciones existentes en el mundo real. Los datos, que han de ser compartidos por diferentes usuarios y aplicaciones, deben mantenerse independientes de estas, y su definición y descripción únicas para cada tipo de dato, que han de ser almacenadas junto con los mismos.
Toda base de datos debe cumplir con una serie de requisitos, a los que no podemos referir como objetivos de los sistemas de base de datos.
Una base de datos bien diseñada le brinda un completo acceso a la información deseada. Con un buen diseño dedicará menos tiempo a crear la base de datos y obtendrá resultados más exactos en menos tiempo.
El primer paso para crear una base de datos relacional, según (Martínez, 2006, p.
47) es planificar el tipo de información que se quiere almacenar, teniendo en cuenta dos
aspectos:
- La información disponible
- La información que necesitamos
Para el diseño se deben seguir los siguientes pasos:
- Determinar el propósito de la base de datos.
- Determinar las tablas necesarias.
- Determinar los campos necesarios en cada tabla.
- Determinar las relaciones.
- Refinar el Diseño.
Referencia Bibliográfica: Diseño de bases de datos relacionales. Escrito por JOSÉ MANUEL PIÑEIRO GÓMEZ
Referencia Bibliográfica: Jackson, G. A. Introducción al diseño de bases de datos relacionales. Madrid: Anaya, 1990.
Referencia Web: https://www.ecured.cu/Base_de_datos_relacional
CAMPO
En informática, un campo es un espacio de almacenamiento para un dato en particular.
En las bases de datos, un campo es la mínima unidad de información a la que se puede acceder; un campo o un conjunto de ellos forman un registro, donde pueden existir campos en blanco, siendo este un error del sistema operativo. Aquel campo que posee un dato único para una repetición de entidad, puede servir para la búsqueda de una entidad específica.
En las hojas de cálculo los campos son llamados "celdas".
Podemos agregar muchos tipos de campos que formarán parte de nuestra base de datos. Cada campo admite distintos tipos de datos, con diferentes interfaces. Después de crear los campos deseados podemos añadir información en la base de datos.
Un campo es el nombre de la unidad de información. Cada entrada en una base de datos puede tener múltiples campos de diversos tipos. Por ejemplo, un campo de texto llamado 'color favorito', que permite escribirlo, o un menú llamado 'población' que permita escoger de un listado de poblaciones posibles. La combinación de campos diversos nos permitirá recabar toda la información que consideremos relevante sobre los ítems que constituyen la base de datos.
Tipos de campos
- Caja de selección
- Fecha
- Archivo
- Menú
- Menú (selección múltiple)
- Número
- Dibujo
- Botones de radio
- Texto
- Área de texto
- URL
Todos los campos necesitan un nombre y una descripción cuando se crean.
Las cajas de selección múltiple se pueden utilizar, por ejemplo, en una base de datos de películas, que pueden ser de horror, comedia, del oeste, etc. En este caso se podrían seleccionar combinaciones de géneros, por ejemplo horror-comedia o comedia-del oeste.
El campo Menú (selección múltiple) también permite una selección de opciones, pero en este caso clicando en un menú (lo cual a menudo no resulta tan obvio como seleccionar una opción).
Permite que los usuarios entren una fecha seleccionando en un listado desplegable el día, mes y año correspondientes.
Permite que los usuarios suban un fichero desde su ordenador. Si se trata de un fichero de imagen sería mejor opción seleccionar el campo dibujo,etc...
Referencia bibliográfica: Gomez, M (2013), Notas base de Datos. México
Referencia Web: https://docs.moodle.org/all/es/19/Campos_de_la_base_de_datos

REGISTRO
Los registros constituyen la información que va contenida en los campos de la tabla, por
ejemplo: el nombre del paciente, el apellido del paciente y la dirección de este. Generalmente los
diferentes tipos de campos que se pueden almacenar son los siguientes: Texto (caracteres),
Numérico (números), Fecha / Hora, Lógico (informaciones lógicas si/no, verdadero/falso, etc.),
imágenes.
Un registro es el equivalente informático a una ficha. Los registros se componen de campos, que son las zonas de información en las que se articula un registro. Los registros y los ficheros son unidades de trabajo básicas en informática, y no sólo en el terreno de las bases de datos. Los ficheros y los registros se usaban antes de que existieran aquellas y se usan, en general, en cualquier situación donde sea necesario estructurar conjuntos de datos. Por ello, hay aplicaciones informáticas que son capaces de crear y gestionar ficheros, es decir, que permiten definir estructuras de registros, dar registros de alta, recuperarlos, modificarlos, etc.
En informática, o concretamente en el contexto de una base de datos relacional, un registro (también llamado fila o tupla) representa un objeto único de datos implícitamente estructurados en una tabla. En términos simples, una tabla de una base de datos puede imaginarse formada de filas y columnas o campos. Cada fila de una tabla representa un conjunto de datos relacionados, y todas las filas de la misma tabla tienen la misma estructura.
Un registro es un conjunto de campos que contienen los datos que pertenecen a una misma repetición de entidad. Se le asigna automáticamente un número consecutivo (número de registro) que en ocasiones es usado como índice aunque lo normal y práctico es asignarle a cada registro un campo clave para su búsqueda.
- En primer lugar, un registro del sistema viene a ser una base de datos que tiene el fin de almacenar configuración, opciones y comandos propios del sistema operativo. En general, estos registros se utilizan en los sistemas Windows de Microsoft. Un registro de sistema puede contener información y configuraciones del hardware y software en uso, preferencias del usuario, asociaciones de archivos y ficheros, usos de sistema, cambios y modificaciones, etcétera. Estos registros son conservados dentro del sistema con denominaciones como "User.dat" o "System.dat" y pueden ser recuperados por el usuario para su transporte a otro sistema.
- Otro tipo de registro es el de programación. Este tipo de dato está formado por varios elementos en asociación que responden a una misma estructura. Los registros de programación pueden ser elementales o complejos y guardan información sobre cómo el software o aplicación en particular funcionará o actuará en cada momento.
- Por otro lado, en una base de datos también se hace uso de registros. Cada registro representa un ítem o elemento único que se encuentra en una tabla, hoja o base. Así, el registro está configurado por el conjunto de datos que pertenecen a una entidad en particular.
En todos estos casos y otros, el empleo de registros tiene el fin de almacenar información y datos, ponerla en relación y colocarla al alcance bajo un índice o sistema de orden que permita su acceso y uso en cualquier momento.
Referencia Bibliográfica: Cruz, M (S.F) Access Base de Datos. MéxicoReferencia Web: Definicion ABC https://www.definicionabc.com/tecnologia/registro-2.ph
TABLAS

Las tablas se consideran estructuras bidimensionales homogéneas (matrices) compuestas por filas y columnas. Cada tabla está formada por un número fijo de columnas y por un número variable de filas. Las filas se denominan tuplas, cada tupla es un registro, y cada registro representa a una entidad del mundo real; las columnas, por su parte, son los campos del registro, que representan a los diversos atributos de la entidad. El conjunto de los valores que puede adoptar una columna se denomina su dominio.
El álgebra relacional especifica entonces las diversas operaciones que pueden realizarse con las tablas, las cuales generan nuevas tablas. La base para realizar operaciones con dos tablas (cruzar datos) radica en la existencia de por lo menos una columna en ambas tablas cuyos elementos pertenezcan al mismo dominio. Sin embargo, para que las operaciones relacionales se comporten de la forma prevista por el álgebra, las tablas deben estar construidas de acuerdo con unas especificaciones concretas, y de las tablas así construidas se dice que están normalizadas.
Tabla en las bases de datos, se refiere al tipo de modelado de datos, donde se guardan y almacenan los datos recogidos por un programa. Su estructura general se asemeja a la vista general de un programa de hoja de cálculo.
Una tabla es utilizada para organizar y presentar información. Las tablas se componen de filas y columnas de celdas que se pueden rellenar con textos y gráficos.
Las tablas se componen de dos estructuras:
- Registro: es cada una de las filas en que se divide la tabla. Cada registro contiene datos de los mismos tipos que los demás registros. Ejemplo: en una tabla de nombres ,direcciones, etc, cada fila contendrá un nombre y una dirección.
- Campo: es cada una de las columnas que forman la tabla. Contienen datos de tipo diferente a los de otros campos. En el ejemplo anterior, un campo contendrá un tipo de datos único, como una dirección, o un número de teléfono, un nombre, etc.
A los campos se les puede asignar, además, propiedades especiales que afectan a los registros insertados. El campo puede ser definido como índice o autoincrementable, lo cual permite que los datos de ese campo cambien solos o sean el principal a la hora de ordenar los datos contenidos.
Cada tabla creada debe tener un nombre único en la Base de Datos, haciéndola accesible mediante su nombre o su seudónimo (Alias) (dependiendo del tipo de base de datos elegida). La estructura de las tablas viene dada por la forma de un archivo plano, los cuales en un inicio se componían de un modo similar.
Las tablas son los objetos principales de bases de datos que se utilizan para guardar datos.
Según (Juárez, 2006, p. 47) en una tabla es de fundamental importancia identificar las propiedades de un campo como se mostrarán en la siguiente tabla, mismas que son de gran ayuda para el manejo de la apariencia que tienen los campos, evitar la introducción incorrecta de los mismos, especificar valores predeterminados, acelerar la búsqueda y ordenar una tabla mediante índices.
Es un conjunto de datos dispuesto en una estructura de filas y columnas. En una tabla las filas se denominan registros y las columnas campos; la primera fila contiene los nombres de campo. Cada campo contiene determinado tipo de datos y tiene una longitud expresada en el número de caracteres máximo del campo. Para crear una tabla es necesario definir su estructura:
- El nombre de la tabla
- Los tipos de dato de cada campo
- Las propiedades o características de cada campo
- El campo clave
La planificación de la estructura de la base de datos, en particular de las tablas, es vital para la
gestión efectiva de la misma. El diseño de la estructura de una tabla consiste en una descripción
de cada uno de los campos que componen el registro y los valores o datos que contendrá cada
uno de esos campos.
Referencia Bibliografica: Austing, R. H.; Caseel, L. N. Gestión de ficheros: organización y métodos de acceso. Madrid: Anaya, 1991.Referencia web: https://www.definicionabc.com/tecnologia/tabla.php
INDICES

Los índices son una forma muy eficiente de ordenar una tabla por uno o varios campos. La ordenación es virtual, es decir, no hay cambio del lugar físico de los registros, sino que se hace en un archivo de índices. Cuando se activa un índice, el acceso a los registros se realiza de acuerdo al orden establecido por él.
Todo índice tiene un nombre, un tipo, una expresión y un sentido. Opcionalmente, puede usar un filtro.
El nombre es arbitrario y puede tener hasta 10 posiciones. Hay diferentes tipos de índices, con distintos efectos, como veremos. El sentido puede ser ascendente o descendente. El filtro discrimina qué registros van a ser considerados para construir el índice.
La expresión es el criterio por el cual se van a indexar los registros. Puede consistir en uno o más campos de la tabla, o expresiones más complejas sobre ellos. Por ejemplo, si se quiere ordenar la tabla de artículos por el código, se usará éste para construir el índice. Tratándose de una expresión que use un único campo, este puede ser de cualquier tipo, sin necesidad de transformarlo. Para construir un índice por varios campos o ex- presiones sobre ellos, hay que crear una expresión final de tipo carácter. Supongamos que queremos indexar el archivo de ventas por código de cliente y número de factura. Si ambos campos son de caracteres, la expre- sión del índice será código + factura. Si el código fuera de caracteres y la factura numérica, la expresión ante- rior sería errónea, pues los componentes de la expresión deben ser de caracteres para que la expresión total sea de tal tipo. En este caso, sería necesario convertir la factura a caracteres, mediante la función STR( ). La expresión correcta, entonces, sería código + str(factura, x), suponiendo que factura tiene tamaño x, sin deci- males. Si el código también fuera numérico, la expresión sería str(código, z) + str( factura, x), suponiendo que el tamaño del código fuera z, sin decimales. Para los campos fecha o fecha hora, cuando se usan con otros campos para construir la expresión del índice, es necesario transformarlos a caracteres, usando la función DTOS( ).
Dado que el ordenamiento se hace en un archivo de índices, sin afectar la tabla, ésta puede tener todos los índices que sean necesarios.
Tipos de archivos de índices:
Hay archivos de índices simples y compuestos. Los simples solamente pueden almacenar un ordenamiento. Su extensión es IDX. Dado que las tablas pueden sufrir altas, bajas y cambios de registros, para que tales cambios queden reflejados en lo índices, hay que someterlos a comandos específicos.
Los archivos de índices compuestos pueden almacenar varios ordenamientos, cada uno con un nombre dife- rente. Su extensión es CDX. Pueden ser no estructurales y estructurales. Los no estructurales tienen un nom- bre distinto al de la tabla que ordenan. Como sucede con los índices simples, deben someterse a comandos específicos para que reflejen los cambios en las tablas.
Los archivos de índices estructurales tienen el mismo nombre de la tabla a la cual ordenan. Cuando se abre la tabla, todos los índices están disponibles y se actualizan automáticamente a medida que la tabla sufre cambios, sin necesidad de comandos específicos. Esto hace de los índices compuestos estructurales los más útiles, por lo que puede prescindirse de los anteriores.
Para abrir una tabla con un índice compuesto estructural activo, se emite el comando USE con la opción ORDER. Para cambiar posteriormente el índice activo, se usa el comando SET ORDER.
Referencia Bibliográfica: Caceres, E (2008). Tablas, Base de Datos e Indices.
TIPOS DE DATOS DE ACCESS

La potencia de un sistema de gestión de Access surge de su capacidad para buscar, localizar y combinar rápidamente información almacenada en distintas tablas para que Access funcione eficientemente, cada tabla de la base de datos debe incluir un campo o una serie de campos que identifique inequívocamente cada fila o registro individual almacenado en la tabla.
En la terminología de base de datos, esta información identificadora se denomina clave principal de la tabla, la cual permite asociar rápidamente datos de distintas tablas y poderlos presentar conjuntamente.
Para elegir los campos de clave principal se debe tener en cuenta
Access no permite la existencia de valores duplicados o nulos en un campo de clave principal.
Puede utilizar el valor del campo de clave principal para buscar registros, por lo que dicho campo no debe ser demasiado largo, y si fácil de recordar y escribir por lo que puede convenir que tenga un número limitado de letras o dígitos o que esté dentro de un determinado rango.
El tamaño de la clave principal influye en la velocidad de las operaciones en la base de datos por lo que para un máximo rendimiento, utilice el menor tamaño posible para que quepan los valores a almacenar en el campo.
Determinar las relaciones
Access es un sistema de administración de base de datos relacionales lo que significa que es posible almacenar datos relacionados en distintas tablas de la base de datos
Los diferentes tipos de datos de Access son:
- Texto: permite almacenar cualquier tipo de texto, tanto caracteres como dígitos y caracteres especiales. Tiene una longitud por defecto de 50 caracteres, siendo su longitud máxima de 255 caracteres. Normalmente se utiliza para almacenar datos como nombres, direcciones o cualquier número que no se utilice en cálculos, como números de teléfono o códigos postales.
- Memo: se utiliza para textos de más de 255 caracteres como comentarios o explicaciones. Tiene una longitud máxima de 65.536 caracteres. Access recomienda para almacenar texto con formato o documentos largos adjuntar el archivo. En Access 2010 se puede ordenar o agrupar por un campo Memo, pero sólo se tendrán en cuenta para ello los 255 primeros caracteres.
- Número: para datos numéricos utilizados en cálculos matemáticos. Dentro del tipo número la propiedad tamaño del campo nos permite concretar más. En resumen los tipos Byte, Entero y Entero largo permiten almacenar números sin decimales; los tipos Simple, Doble y Decimal permiten decimales; el tipo Id. de réplica se utiliza para claves autonuméricas en bases réplicas.
- Fecha/Hora: para la introducción de fechas y horas desde el año 100 al año 9999.
- Moneda: para valores de dinero y datos numéricos utilizados en cálculos matemáticos en los que estén implicados datos que contengan entre uno y cuatro decimales. La precisión es de hasta 15 dígitos a la izquierda del separador decimal y hasta 4 dígitos a la derecha del mismo. Access recomienda utilizar el tipo Moneda para impedir el redondeo de cifras en los cálculos. Un campo Moneda tiene una precisión de hasta 15 dígitos a la izquierda de la coma decimal y 4 dígitos a la derecha. Un campo Moneda ocupa 8 bytes de espacio en disco.
- Autonumeración: número secuencial (incrementado de uno a uno) único, o número aleatorio que Microsoft Access asigna cada vez que se agrega un nuevo registro a una tabla. Los campos Autonumeración no se pueden actualizar.
- Sí/No: valores Sí y No, y campos que contengan uno de entre dos valores (Sí/No, Verdadero/Falso o Activado/desactivado).
- Objeto OLE: objeto como por ejemplo una hoja de cálculo de Microsoft Excel, un documento de Microsoft Word, gráficos, imágenes, sonidos u otros datos binarios. Si trabajas con bases de datos creadas con otras versiones de Access, los archivos insertados como objeto OLE seguirán funcionando perfectamente. Pero si lo que estás haciendo es crear una nueva base de datos, es interesante que no utilices este tipo de datos, porque a partir de la versión 2007 empezó a considerarse obsoleto y a utilizar, en su lugar, el tipo Datos adjuntos que veremos más adelante.
- Hipervínculo: texto o combinación de texto y números almacenada como texto y utilizada como dirección de hipervínculo. Una dirección de hipervínculo puede tener hasta tres partes: Texto: el texto que aparece en el campo o control. Dirección:ruta de acceso de un archivo o página. Subdirección: posición dentro del archivo o página. Sugerencia: el texto que aparece como información sobre herramientas.
- Datos adjuntos: Puede adjuntar archivos de imágenes, hoja de cálculo, gráficos y otros tipos de archivos admitidos, a los registros de la base de datos de forma similar a como adjunta archivos a los mensajes de correo electrónico. Los campos de datos adjuntos ofrecen mayor flexibilidad que los campos de tipo Objeto OLE, y utilizan el espacio de almacenamiento de manera más eficaz porque no crean una imagen de mapa de bits del archivo original.
- Calculado: Un campo calculado es un campo cuyo valor es resultado de una operación aritmética o lógica que se realiza utilizando otros campos. Por ejemplo podría ser un campo Total que calcula su valor multiplicando Precio * Cantidad en una línea de pedido.
Referencia Web: http://nelsonjuliaomartinez.overblog.com/los-tipos-de-datos-en-access-an%C3%A1lisis-de-6-30pm-a-8-30pm-semanal